Encodage des caractères (ASCII, UTF-8)
Objectif de l’encodage des caractères
-
Représenter du texte en binaire pour le stockage et la transmission.
-
Associer un code numérique unique à chaque caractère d’un texte selon un format standardisé (ASCII, ISO8859-x, UTF-8, UTF-16, …).
-
Chaque format associe caractère ⇆ nombre ⇆ suite de bits.
ASCII
-
ASCII = American Standard Code for Information Interchange
-
Norme d’encodage apparue dans les années 60
-
Caractères codés sur 7 bits (→ ASCII standard) ou 8 bits (→ASCII étendu)
-
l’ASCII standard ne prend en charge que les caractères de la langue anglaise (⇒ pas d’encodage prévu pour les lettres accentuées)
-
ASCII 7 bits (128 caractères : 0–127)
-
0–31 : caractères de contrôle
-
32–126 : caractères imprimables
-
127 : DEL (Delete)
 Table ASCII 7 bits
Table ASCII 7 bits
-
-
ASCII étendu 8 bits (256 caractères : 0-255)
-
128 premiers caractères codés comme en ASCII standard
-
Variantes nationales (ISO‑8859‑1, ISO-8859-15, Windows‑1252…) pour les caractères 128-255
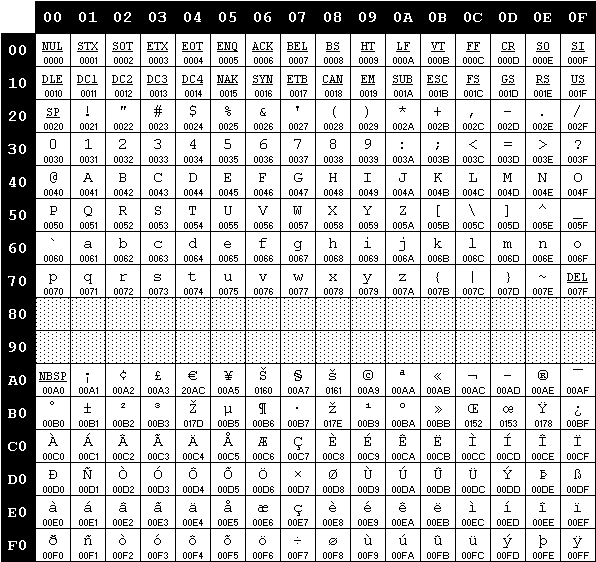 Table ASCII étendu ISO 8859-15
Table ASCII étendu ISO 8859-15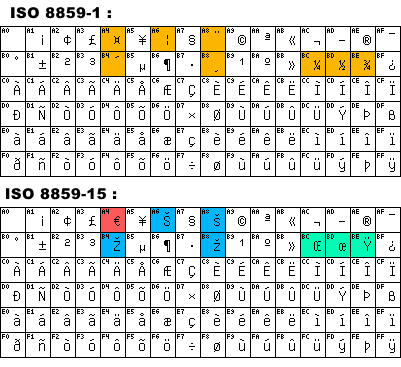 ISO 8859-1 vs. ISO 8859-15
ISO 8859-1 vs. ISO 8859-15
-
-
ASCII :
‘A’ →65|10 →41|16 →0100 0001|2
‘€’→ pas de code -
ASCII étendu (Windows-1252) :
‘A’ → idem ASCII standard
‘€’→128|10 →80|16 →100 0000|2 -
ASCII étendu (ISO-8859-15) :
‘A’ → idem ASCII standard
‘€’ →164|10 →A4|16 →1010 0100|2
UTF‑8
-
UTF-8: Unicode Transformation Format basé sur des octets (d’où le “-8”) -
Norme d’encodage pour les caractères Unicode apparue en 1992
Unicode n’est pas un encodage mais une norme qui définit l’ensemble des caractères utilisables au niveau mondial et leur attribue un identifiant unique appelé point de code (→ U+xxxxxx)
-
Encodage de plus en plus répandu (utilisé par 95.2% des sites web en 2020)
-
Compatible à 100% avec l’encodage ASCII
-
Code sur 1 à 4 octets les points de code du standard Unicode :
Points de code Nombre d’octets U+0000 → U-007F
(Caractères ASCII)1
U+0080 → U+07FF
2
U+0800 → U+FFFF
3
U+10000 → U+10FFFF
(émojis…)4
-
‘A’ (U+0041) → 41|16
-
‘é’ (U+00E9) → C3 A9|16
-
‘€’ (U+20AC) → E2 82 AC|16
-
‘😊’ (U+1F60A) → F0 9F 98 8A|16
|
Byte Order Mark (BOM) :
On trouve parfois au début d’un fichier texte, une séquence d’octets qui ne fait pas partie du texte mais qui signale un encodage unicode (UTF-16, UTF-32, UTF-8) ainsi que l’ordre des octets : le Byte Order Mark (BOM). Cette marque est indispensable pour les encodages UTF-16 et UTF-32 mais absolument pas pour UTF-8. Elle apparaît cependant parfois avec la valeur C’est ce qui peut expliquer l’affichage des caractères “” avant le contenu réel du fichier lorsque celui-ci est affiché en tant que texte codé en ISO8859-1. On retiendra qu’il vaut mieux configurer son éditeur de texte pour qu’il n’insère pas ce BOM lors de l’enregistrement des fichiers en UTF-8 ( dans VSCode). |
Ressources complémentaires
-
Character encoding: Types
→ un article très complet sur l’encodage des caractères
Mini‑exercices de conversion
-
Utiliser les tables ASCII / UTF-8 ou un convertisseur en ligne pour répondre aux questions suivantes :
-
Quel caractère correspond au code ASCII
0100 0010|2 ?Solution
0100 0010|2 =66|10 =42|16 → ‘B’ -
Quel est le code UTF‑8 du caractère ‘ß’ (U+00DF) ?
Solution
‘ß’ (U+00DF) →
C3 9F|16 -
Quel symbole correspond au code UTF‑8
E2 82 AC|16 ?Solution
E2 82 AC|16 → ‘€’ -
Quelle lettre correspond au code ISO-8859-1
1110 0000|2=E0|16 ?Solution
1110 0000|2=E0|16 =224|10 → 'à’
-
-
Déterminer manuellement le point de code du caractère ‘∑’ sachant que son codage UTF-8 est E2 88 91|16 ?
Réponse
‘∑’ → U+2211
-
Déterminer manuellement l’encodage UTF-8 du point de code U+1F44D
Réponse
U+1F44D → F0 9F 91 8D|16 (‘👍’)
🞄 🞄 🞄